Terse notes on CNN’s.
- Convolution
- Kernel
- Pooling
- Feed Forward Classification
Convolution
A convolution combines information about local pixels such that pixels close to each other in an image are ”summarized” by a smaller set of pixels.
A discrete convolution is defined like so:
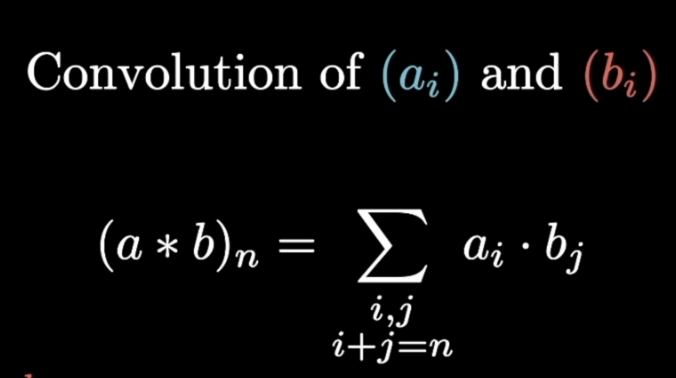
A continuous convolution is defined like so:
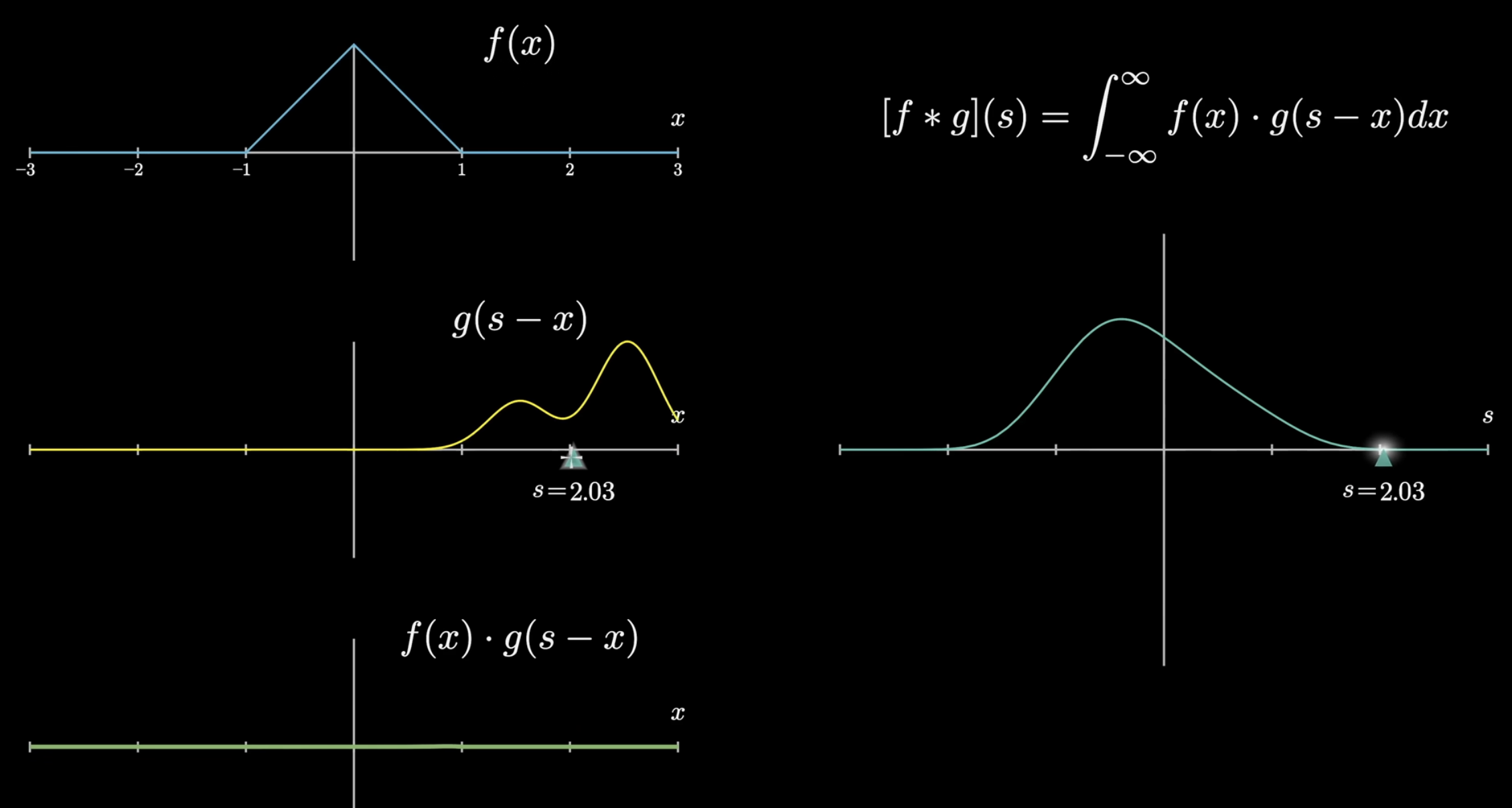
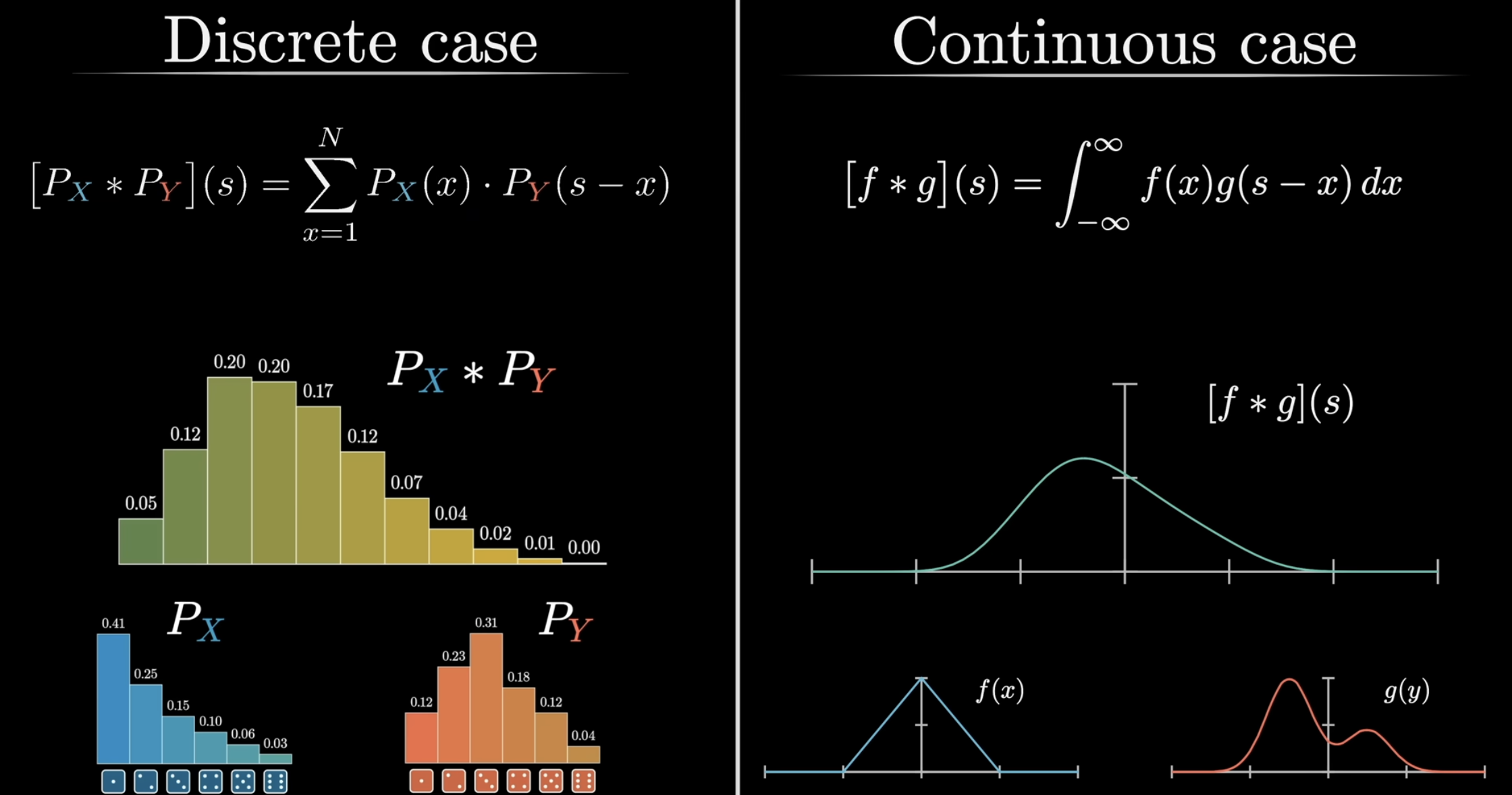
Comparison
Kernel
In a CNN, the kernel refers to a filtered sampling window. For more insight, I like to refer to the Romance languages, which confer terms literally translating as nucleus (Spanish, Portuguese) or center (French).
For example, a Gaussian blur can be achieved by iterating a 5x5 kernel over an image in which the weights are normally distributed from the center pixel going outwards. Therefore, the effect is that the central pixel is emphasized, while gaining marginal color from its neighbors, achieving a blur.
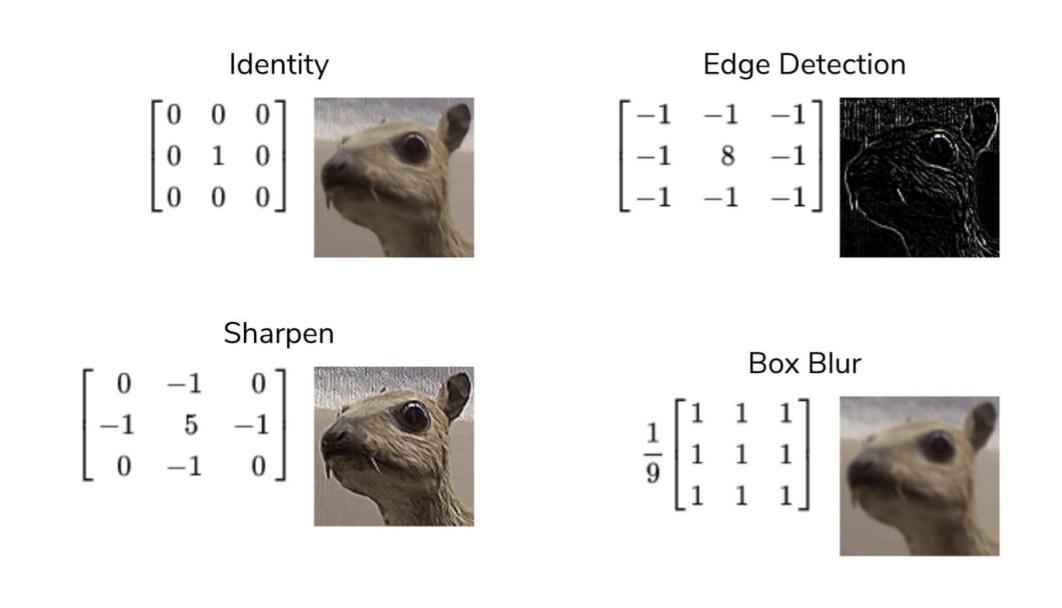
Kernels are leveraged to downsample from the data. Here are some examples
Comparison
Pooling:
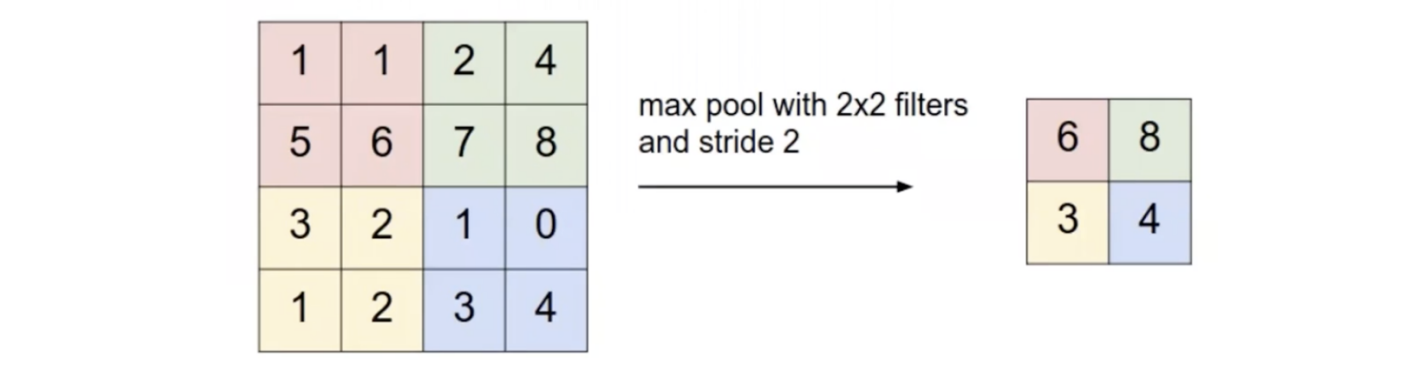
Pooling is another similar operation to convolutions done on an image. Sometimes, applying a convolution to an image doesn’t reduce an image enough, so we can further utilizing pooling operations. Pooling is a lot more simple than applying a convolution in that we do not have a kernel full of elements. Instead, we have a filter that we slide across the image, and for every position of this filter, we simply take the minimum, maximum, mean, or median, of the set of pixels inside the image that fall underneath this filter. It is most typical to use a max pool with a 2x2 filter and a 2x2 stride, such that there is no overlap between filters. Using max pool has seemed to work better than the average pool.
Here is a concrete example of a pool:
Microsoft Phi3 Lecture
What is a Convolutional Neural Network?
A Convolutional Neural Network (CNN) is a type of feedforward neural network that uses convolutional and pooling layers to extract features from images or other data with grid-like topology. The key characteristics of a CNN are:
- Convolutional Layers: These layers use small filters to scan the input data, performing a dot product at each position to generate a feature map.
- Pooling Layers: These layers downsample the output of convolutional layers, reducing the spatial dimensions and increasing the robustness to small translations.
- Activation Functions: CNNs typically use ReLU (Rectified Linear Unit) or Sigmoid activation functions in hidden layers.
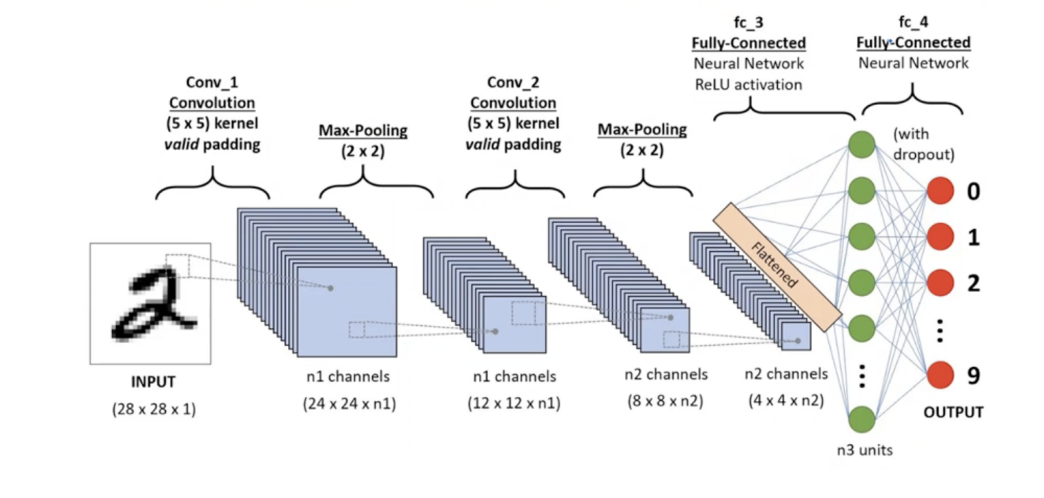
Architecture
A typical CNN architecture consists of:
- Input Layer: The input layer receives the raw data, such as an image.
- Convolutional Layers: One or more convolutional layers extract features from the input data.
- Pooling Layers: One or more pooling layers downsample the output of convolutional layers.
- Flatten Layer: The flatten layer reshapes the output into a 1D array, which is then fed into fully connected (dense) layers.
- Dense Layers: One or more dense layers perform classification or regression tasks.
How CNNs Work
Here’s a step-by-step explanation of how a CNN works:
- Data Input: The input data (e.g., an image) is fed into the CNN.
- Convolutional Layer: The convolutional layer applies filters to the input data, generating a feature map.
- Activation Function: The activation function (e.g., ReLU) is applied to the output of the convolutional layer.
- Pooling Layer: The pooling layer downsamples the output of the convolutional layer.
- Repeat Steps 2-4: This process is repeated multiple times, with each convolutional layer extracting more abstract features from the input data.
- Flatten Layer: The output of the convolutional layers is flattened into a 1D array.
- Dense Layers: One or more dense layers perform classification or regression tasks using the flattened output.
Applications
CNNs have numerous applications in computer vision, including:
- Image Classification: CNNs are widely used for image classification tasks, such as object recognition and scene understanding.
- Object Detection: CNNs can detect objects within images, including people, animals, and vehicles.
- Segmentation: CNNs can segment specific regions or objects from an image.
- Image Generation: CNNs can generate new images based on patterns learned from a dataset.
Key Advantages
- Robustness to Small Translations: CNNs are robust to small translations, thanks to the pooling layers.
- Ability to Extract Abstract Features: CNNs can extract abstract features from input data, such as edges and textures.
- Flexibility in Architecture: CNNs can be customized with different numbers of convolutional and pooling layers.