수고하세요!
수고하세요 … what a wonderful phrase, it means work-hard, 화이팅 for the rest of your days!
A casual farewell rooted in Korean work culture, the upper politeness register manifests as
수고하셨어요, used as:
- Cashier is a colleague ~ “great job working a full day today + goodbye”
- Cashier has done great effort ~ “great effort!”
In that case, you (as the customer) could say 수고하셨습니다 as a way to say thanks (a gesture of gratitude).
So, working hard is as common as invoking Catholic Jesus in Latin culture?
Why, yes! You’re catching on!
Shtetl Optimizations of the Umbral Calculi
In mathematics, the umbral calculus is a technique where you pretend that subscript indices are exponents. Umbra is Latin for “shadow.” The method is, on its face, absurd – and yet it works.
The classic example: the Bernoulli polynomials. The ordinary binomial expansion gives you
\[(y + x)^n = \sum_{k=0}^{n} \binom{n}{k} y^{n-k} x^k\]and the Bernoulli polynomials satisfy a remarkably similar identity:
\[B_n(y + x) = \sum_{k=0}^{n} \binom{n}{k} B_{n-k}(y) \, x^k\]The umbral move? Pretend the subscript in $B_{n-k}$ is an exponent $b^{n-k}$, so that $B_n(x) = (b + x)^n$. Differentiate that, and you get $B_n’(x) = n(b+x)^{n-1} = nB_{n-1}(x)$ – the correct result, derived by treating a shadow as the real thing. John Blissard introduced this in 1861; Gian-Carlo Rota made it rigorous a century later by defining a linear functional $L$ such that $L(z^n) = B_n$, explaining why the shadow-trick works.
What does this have to do with blogs? Consider a blog’s readability metrics as shadows of the writing itself. A Flesch-Kincaid score is not the prose, just as a subscript is not an exponent. And yet, by treating these shadows as if they were the real thing – by pretending indices are exponents – we can derive surprising identities between blogs that otherwise look nothing alike. The Gunning Fog index of a quantum computing post and a personal finance post might converge, despite the posts sharing nothing in vocabulary or intent. The shadow knows something the text doesn’t say directly.
Scott Aaronson’s blog, Shtetl Optimized, is a national treasure. The man wittily demagogues on science, life, politics, and vagina dentata with equal aplomb. The purpose of this post was to scrutinize the shape and form of a shtetl (optimized blog), starting with a distance metric.
Linguistic Complexity: Blog vs. Blog
Here, I analyze the linguistic complexity of Aaronson’s blog compared to my own and two others: the also great Simon Willison blog along with the ineffable Alex Harri blog.
| Source | Flesch-Kincaid Grade | ARI Grade | Gunning Fog Grade | Lexical Diversity | Word Count |
|---|---|---|---|---|---|
| alexharri_posts.csv | 9.77 | 9.55 | 12.40 | 0.228 | 3,866.5 |
| juleshenry_posts.csv | 15.51 | 16.31 | 17.78 | 0.458 | 2,000.4 |
| scottaaronson_blog_posts.csv | 13.01 | 13.31 | 15.61 | 0.543 | 966.8 |
| simonwillison_all_blogs.csv | 12.13 | 12.55 | 14.52 | 0.554 | 627.8 |
Writing Stats Over Time
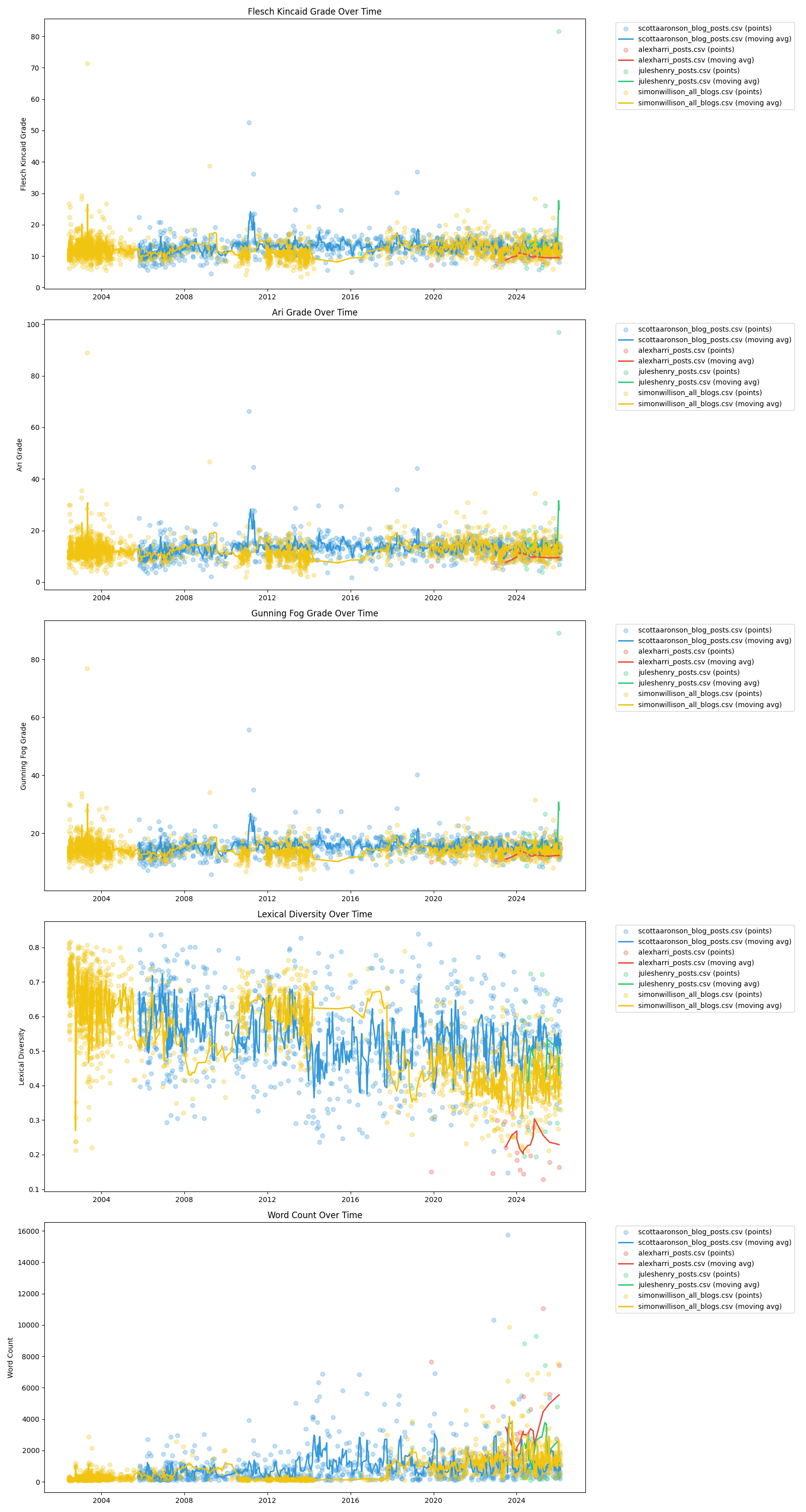
The curiosity? Technical posts register as more sophisticated when code is used because code has no “periods”, qualifying as long Faulknerian sentences. Note the outliers in my own blog achieve Flesch-Kincaid of 80+. Therefore, I also include an outliers-removed summary to truly compare. Alex Harri, an Icelander, unsurprisingly writes at a lower grade level, even though his posts are incredibly engaging and informative. Simon Willison’s posts are more accessible, while Scott Aaronson’s are more complex, likely due to their technical density.
Interquartile Reduction of Outliers
| Source | Flesch-Kincaid Grade | ARI Grade | Gunning Fog Grade | Lexical Diversity | Word Count |
|---|---|---|---|---|---|
| alexharri_posts.csv | 9.86 | 9.64 | 12.49 | 0.234 | 3,443.41 |
| juleshenry_posts.csv | 11.50 | 11.33 | 13.58 | 0.500 | 1,110.80 |
| scottaaronson_blog_posts.csv | 12.77 | 13.01 | 15.35 | 0.559 | 702.75 |
| simonwillison_all_blogs.csv | 11.80 | 12.12 | 14.21 | 0.568 | 482.81 |
A ha! So I do not write at a higher level than Scott or Simon, although I tend to be more verbose.
Writing Stats Over Time Without Outliers
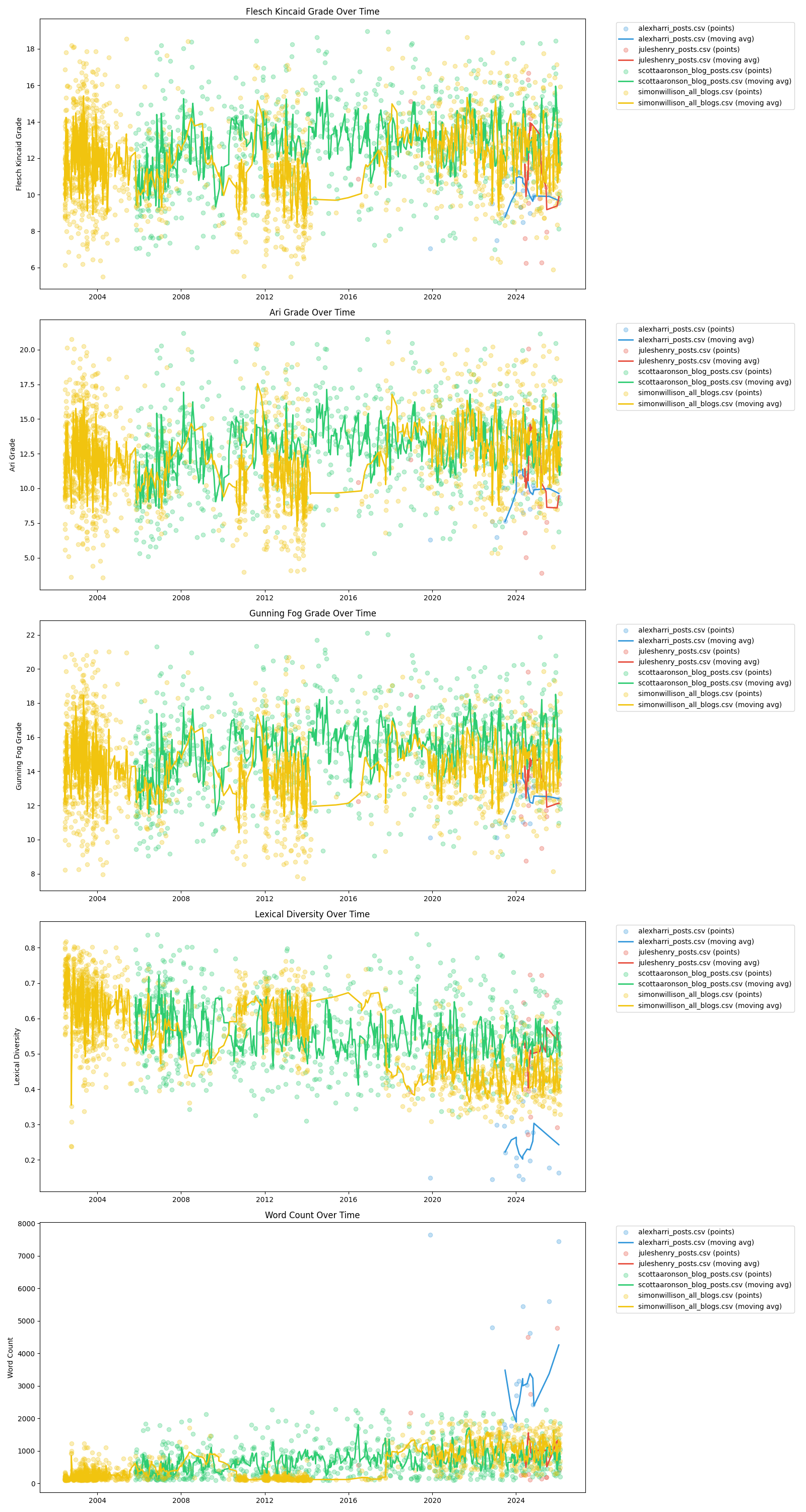
That this analysis was done on Valentine’s Day is perhaps a data point in itself. Scott, solve NP vs. P when you have the chance, will ya?
Code analysis repository found here.